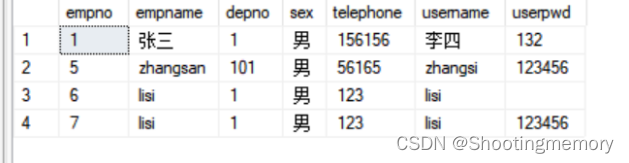
在自然语言处理领域,人们经常需要比较字符串,这些字符串可能是单词、句子、段落甚至是整个文档。如何快速判断两个单词或句子是否相似,或者相似度是好还是差。这类似于我们使用手机打错一个词,但手机会建议正确的词来修正它,那么这种如何判断字符串相似度呢?本文将详细介绍这个问题。
字符串相似度
当我们有两个数字时,我们可以通过从一个数字中减去另一个数字并观察结果的符号和大小来轻松比较它们。这种比较方式也可以用于向量,并且有许多方法可以做到这一点。例如常见的:余弦距离、欧几里得距离、曼哈顿距离、闵可夫斯基公式的p距离等等
但是对于字符串来说就比较复杂了,因为有时需要比较单词、句子或一般的字符串。一种简单的方法是比较字符串或单词之间的公共字母。
总的来说,有三种主要类型的算法用于衡量字符串的相似度,我们将一一介绍:
- 基于编辑的算法
- 基于令牌的算法
- 基于序列的算法

基于编辑的算法
基于编辑的算法,也被称为基于距离的算法,通过测量将一个字符串转换成另一个字符串所需的最少单字符操作(插入、删除或替换)数量来衡量。操作次数越多,相似度(距离)就越低(高)。这一指标为许多其他字符串相似度技术提供了基础,并广泛用于拼写检查、自动纠错和DNA序列分析。
注意:这里的每个字符和每个操作都具有相同的重要性
1、Hamming 距离
该度量标准用于测量两个等长字符串的不相似度,方法是将一个字符串叠加在另一个字符串上,并计算有多少位置的字符不同。汉明要求是长度一致的,但是一些库可以忽略长度条件,所以算法并不适用于处理长度不相同的2个字符串。
>> import textdistance as td
>> td.hamming('book', 'look')
1
>> td.hamming.normalized_similarity('book', 'look')
0.75
>> td.hamming('bellow', 'below')
3
>> td.hamming.normalized_similarity('Below', 'Bellow')
0.5
在第一个示例中,有一个不同的字符。这使得距离等于1,归一化相似度等于(4-1)/4 = 75%。在第二个示例中,比较“bellow”和“below”,前三个字母相同,但接下来的三个字母不同。因此,距离是3,归一化相似度是(6-3)/6 = 50%。
2、Levenshtein 距离
Levenshtein 距离是最常用的基于编辑的算法,是一个字符串相似度度量标准,用于测量将一个字符串转换成另一个字符串所需的最少单字符允许操作(插入、删除或替换)的数量。它提供了一个量化的度量,表明两个字符串有多不同。它没有像Hamming 距离那样的序列长度条件。
>> td.levenshtein('book', 'look')
1
>> td.levenshtein.normalized_similarity('book', 'look')
0.75
>> td.levenshtein('bellow', 'below')
1
>> td.levenshtein.normalized_similarity('Below', 'Bellow')
0.84
在第一个示例中,可以通过替换一个字母来得到另一个单词,因此归一化相似度是(4-1)/4 = 75%。在第二个示例中,有一个插入操作,因此距离是1,归一化相似度是(6-1)/6 = 84%。
3、Damerau-Levenshtein距离
Damerau-Levenshtein距离是Levenshtein 距离的一个变种,它还包括了置换操作。它测量转换一个字符串到另一个字符串所需的四种操作的数量。置换涉及交换两个相邻字符。
注意:不能置换两个不相邻的符号,因此,“stop”和“spot”之间的距离不是1,而是两次(两次替换)。
>> td.levenshtein('act', 'cat')
2
>> td.levenshtein.normalized_similarity('act', 'cat')
0.34
>> td.damerau_levenshtein('act', 'cat')
1
>> td.damerau_levenshtein.normalized_similarity('act', 'cat')
0.67
Levenshtein需要替换两个字母‘a’和‘c’,但由于这两个字母是相邻的,我们可以使用Damerau-Levenshtein算法通过一次操作进行置换,这样就使相似度结果翻倍。这种算法在自然语言处理领域得到了广泛应用,如拼写检查和序列分析。
4、Jaro 相似度
这个算法不是一种距离测量,而是一个介于0和1之间的相似度得分。
Jaro 算法基于匹配字符的数量以及类似Damerau-Levenshtein的置换,但它没有邻近性约束。该方法使用了一个直观的公式:

只有当s1和s2中的两个字符相同且相距不超过max(|s1|, |s2|)/2 - 1个字符时,才被视为匹配。
如果没有找到匹配字符,那么这两个字符串就被认为不相似,贾罗相似度为0。但如果找到了匹配字符,那么我们就计算置换的数量。
>> td.jaro('bellow', 'below')
0.94
>> td.jaro('simple', 'plesim')
0
>> td.jaro('jaro', 'ajro')
0.92
在第一个示例中,有5个匹配字符和一个插入(这不是置换操作),因此Jaro 相似度为1/3*(5/6+5/5+6/6)。在第二个示例中,有0个匹配字符,因为共同字符不在max(|s1|, |s2|)/2-1的范围内。这就是为什么相似度为0的原因。在最后一个示例中,有4个匹配字符和第一和第二字母之间的1个置换操作,因此相似度为1/3 * (4/4+4/4+3/4) = 0.91。
5、Jaro-Winkler相似度
Jaro-Winkler相似度是Jaro相似度的一种修改。它旨在给字符串的公共前缀更多的权重。这将使得前l个字符相同的字符串得到更高的分数。其公式为:

>> td.jaro("simple", "since")
0.7
>> t.jaro_winkler("simple", "since")
0.76
由于两个字符串有两个共同的前缀字母。Jaro-Winkler相似度大于Jaro相似度:0.7 + 0.12(1–0.7) = 0.7 + 0.06 = 0.76。
6、Smith–Waterman相似度
Smith–Waterman算法是一种动态规划算法,用于寻找两个序列之间的最优局部对齐。与寻找最优全局对齐的Needleman-Wunsch算法不同,Smith–Waterman算法识别序列内最佳匹配的子序列,这使其比Needleman-Wunsch算法更具相关性。
该算法基于一个评分矩阵为每个可能的局部对齐分配一个分数,该矩阵定义了字符对之间的相似性或不相似性。它寻找序列中得分最大的区域,表示最佳的局部匹配。
Smith–Waterman算法在生物信息学中特别有用,用于识别生物序列中的相似区域或基序,如DNA或蛋白质序列,而不是寻找整个序列的相似性。它允许检测可能具有生物学意义的局部相似性。
>> td.smith_waterman("GATTACA", "GCATGCU")
3
>> td.smith_waterman("GATTACA", "GCATGCU")
0.43
基于令牌的算法
基于令牌的算法侧重于根据字符串的构成令牌或单词(但有时令牌只是字符)比较字符串。
1、Jaccard 相似度
Jaccard 距离是衡量两个集合之间相似度的一种方法。它通过比较集合中的共享元素与它们总的组合元素来量化集合的相似程度。要计算它,你需要找到交集(共享元素)的大小除以并集(所有独特元素)的大小。
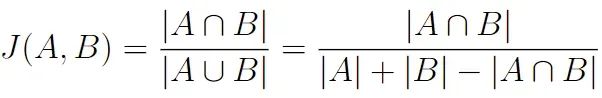
>> td.jaccard('jaccard similarity'.split(), "similarity jaccard".split())
1
>> td.jaccard('jaccard similarity'.split(), "similarity jaccard jaccard".split())
0.66
我们可以看到,Jaccard 相似度并不考虑字符串单词的顺序。
textdistance包的实现考虑了重复元素,但使用上述公式的经典算法在第二个示例中会给出1的结果。如果你没有将序列分割成单词,算法将会将其分割成字符,并对它们应用Jaccard 公式。
如果你了解过目标检测的算法,你会常听到过一个单词 “交并比(Intersection of Union,IoU)”他其实计算的就是Jaccard 相似度。
2、Sørensen-Dice 相似度
Sørensen-Dice 相似度或系数是一种衡量两个集合之间相似度的指标,类似于Jaccard 相似度。它常用于数据分析、文本挖掘和图像处理等领域。你最常听到的一个名字是Dice系数,就是它了。
它的计算方法是找到两个集合之间共享元素(交集)数量的两倍与集合大小之和的比例。相似度的公式如下:

>> td.sorencen('jaccard similarity'.split(), "similarity jaccard".split())
1
>> td.sorencen('jaccard similarity'.split(), "similarity jaccard jaccard".split())
0.8
如果用集合的角度看,把相交作为正类,不相交作为负类,那么我们比较的相似度应该是预测为正类的集合与真实正类集合两者之间的相似度,换成上述四个值理解,也就是:
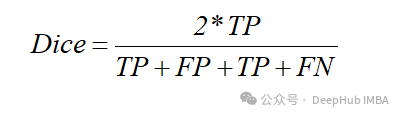
我们再看看f1score的计算公式

F1-score和Dice是相等的,就是这样。
Sørensen-Dice 相似度与Jaccard 相似度唯一的区别是前者更强调共享元素。
Sørensen-Dice相似度在处理二进制数据或元素的存在与否很重要的情况下特别有用。它提供了一种衡量相似度的方法,考虑了集合的大小并强调了共享元素。
它们之间的关系是:
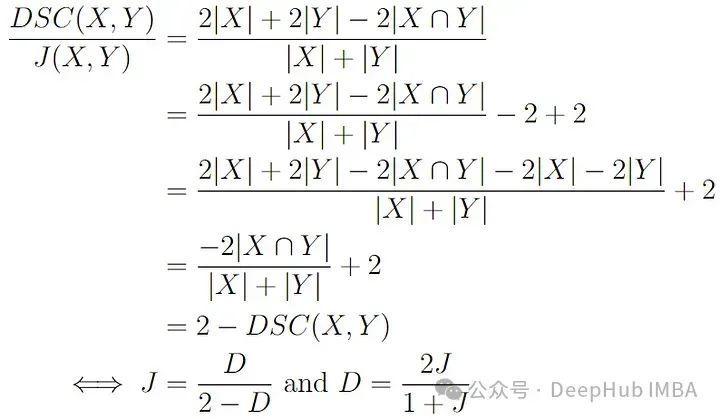
3、Tversky 相似度
Tversky 指数是一种相似度算法,用于量化两个集合之间重叠的程度,同时考虑到假阳性和假阴性。它在处理不平衡数据或集合中元素的存在或缺失具有不同重要性的情况下特别有用。我们可以选择强调共有的词(字符)或非共享的词。
其定义公式如下:

Tversky基指数可以被视为Sørensen-Dice 和Jaccard 算法的一种泛化。
>> td.sorencen('tversky similarity'.split(), "similarity tversky tversky".split())
0.8
>> tversky = td.Tversky(ks=(0.5, 0.5))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.8
>> td.jaccard('tversky similarity'.split(), "similarity tversky tversky".split())
0.67
>> tversky = td.Tversky(ks=(1, 1))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.67
>> tversky = td.Tversky(ks=(0.2, 0.8))
>> tversky('tversky similarity'.split(), "similarity tversky tversky".split())
0.74
Tversky基指数可以平衡集合中不同类型元素的重要性,使其适用于各种应用,如信息检索、数据挖掘和医学诊断。
4、重叠相似度
重叠系数又被称作Szymkiewicz-Simpson系数,是两个集合之间的一种简单相似度。它计算的是集合交集大小与较小集合大小的比例。重叠系数在处理二进制数据或元素的存在与否很重要的情况下特别有用。其公式如下:

这个简单的公式也意味着,如果一个集合是另一个集合的子集。
>> td.overlap('overlap similarity'.split(), "similarity overlap overlap".split())
1.0
5、余弦相似度
余弦相似度是一种广泛使用的相似度测量方法,用于量化多维空间中两个非零向量之间角度的余弦值。它通常用于比较文档、文本或其他高维数据点之间的相似度。余弦相似度捕捉向量的方向或取向,而不是它们的大小。
两个向量A和B之间的余弦相似度公式如下:
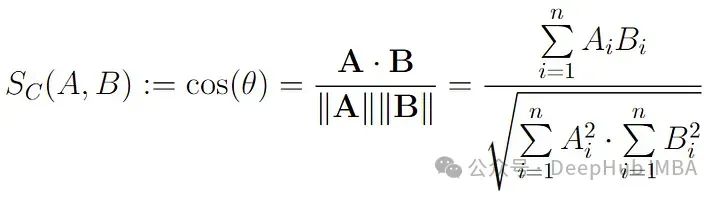
其中A.B表示向量A和B之间的点积,||A||表示向量A的欧几里得范数。
这种相似度测量结果的范围从-1(表示完全相反)到1(表示完全相同)。值为0表示正交或去相关,而介于两者之间的值表示不同程度的相似性或不相似性。
在文本匹配中,属性向量A和B通常表示文档的术语频率向量。余弦相似度作为一种机制,用于在比较时标准化文档长度。在信息检索的背景下,两个文档之间的余弦相似度范围在0到1之间,因为术语频率不能为负。即使使用TF-IDF权重,两个术语频率向量之间的角度也不会超过90°。
>> td.cosine('cosine'.split(), "similarity".split())
0
>> td.cosine('cosine sim'.split(), "cosine sim sim".split())
0.81
textdistance在计算余弦相似度时使用的方法与标准相似度不同。所以建议使用scikit-learn的余弦相似度计算,对于第二个示例,其结果为0.94:
A = [1, 1];B = [1, 2],所以A.B = 3,因此cos(θ) = 3/√(2*5) = 0.94。
6、N-gram相似度
N-gram比较算法是一种通过分析两个字符串中连续n个字符的子序列(称为n-gram)来衡量它们之间相似度的方法。N-gram本质上是从给定字符串中提取的长度为n的子字符串。这种算法常用于文本分析、自然语言处理和相似度比较任务。N-gram比较算法的过程包括以下步骤:
N-gram提取:将每个输入字符串分割成重叠的n个字符的序列。
计数N-gram:统计两个字符串中每个独特n-gram的出现次数。
计算相似度:比较两个字符串之间的n-gram计数,并计算相似度分数。相似度分数可以使用各种度量方法计算,常用的选项包括贾卡德相似度和余弦相似度。
让我们举一个例子,比较两个有拼写错误的单词:(trigrasm 和 trigrams)
>> trigrams = {"tri", "rig", "igr", "gra", "ram", "ams"}
>> trigrasm = {"tri", "rig", "igr", "gra", "ras", "asm"}
# there are 8 unique grams in our example so
# there are 4 shared words and 4 different ones
>> result = 4/8
0.5
N-gram比较对于各种与文本相关的任务非常有用,例如文档相似度分析、抄袭检测和机器翻译。它捕捉文本中的局部模式,并可以提供关于字符串结构相似性的洞察。选择n(n-gram的长度)可以影响比较的粒度和敏感性。但是当处理短字符串时,这种算法会失效,其缺点在于该算法对不同的grams给予了更多的重视,而不是共享的grams。
基于序列的算法
基于序列的算法更侧重于分析和比较整个序列,而不是像基于令牌的算法那样比较序列中的令牌。这些算法在处理DNA序列、蛋白质序列或自然语言句子时尤其有价值。这里有一些示例性的例子:
1、Ratcliff-Obershelp相似度
Ratcliff-Obershelp相似度或Gestalt模式匹配是一种字符串相似度测量方法,侧重于基于两个字符串之间的共同子字符串来找到相似性。它特别适用于比较具有相似结构但可能在细微修改、删除或插入方面有所不同的字符串。该算法根据两个字符串之间最长公共子字符串的长度分配相似度分数。
Ratcliff-Obershelp算法的工作方式如下:
找到最长公共子字符串(LCS),在两个输入字符串之间识别最长的公共子字符串。这是通过找到在两个字符串中以相同顺序出现的公共字符序列来完成的。
然后首先移除LCS部分,并在同一位置进行分割。这将字符串分割成两部分:一部分在公共部分的左边,另一部分在右边。然后取两个字符串的左部分,再次应用此过程以找到它们的LCS。同样的过程也适用于右部分。继续递归这个过程,直到任何分割部分小于一定的设定值。
最后使用前面提到的Sorensen-Dice公式计算相似度分数。这个分数是共享字符数的两倍,除以两个字符串中的总字符数。
下面通过比较“RO pattern matching”和“RO practice”来清晰地解释这个算法。
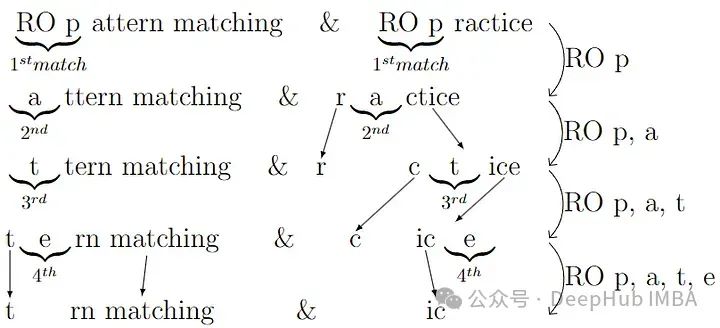
共同的子字符串是“RO p”(4个字符)、‘a’(1个字符)、‘t’(1个字符)、‘e’(1个字符)。这意味着相似度为2*(4+1+1+1)/(19 + 11)=0.467。
但是这个算法有两个致命的缺点,第一个是它的复杂性,为O(n³),另一个是该算法不是可交换的,这意味着D(X, Y) != D(Y, X)。
对于第二个问题,我们来验证一下,第一个例子我们有D(“RO pattern matching”, “RO practice”)。让我们计算另一种方式:
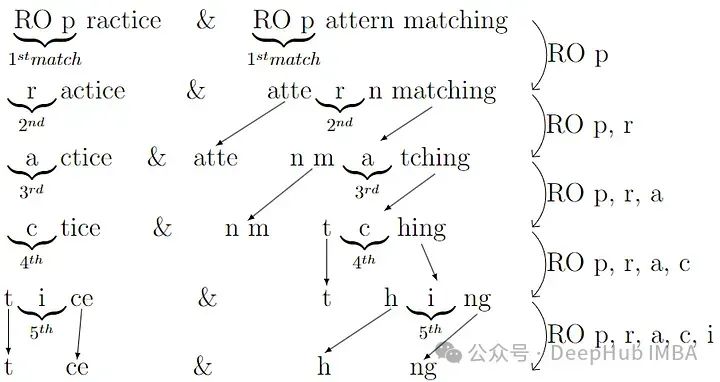
>> s1, s2 = "RO PATTERN MATCHING", "RO PRACTICE"
>> td.ratcliff_obershelp(s1, s2), td.ratcliff_obershelp(s2, s1), len(s1), len(s2)
(0.46, 0.53, 19, 11)
共同的子字符串是“RO p”(4个字符)、‘r’(1个字符)、‘a’(1个字符)、‘c’(1个字符)、‘i’(1个字符)。这意味着相似度为2*(4+1+1+1+1)/(19 + 11)=0.53。
这个例子展示了Ratcliff-Obershelp算法不可交换性的特点,即从不同的方向比较相同的字符串对可能得到不同的相似度分数。这一性质在需要对称相似度的应用中可能是一个限制。
2、最长公共子字符串/子序列相似度
最长公共子字符串算法是一种字符串相似度算法,专注于找出两个字符串之间的最长公共子字符串。它通过识别两个字符串共享的最长连续字符序列来衡量字符串之间的相似度。相似度得分可以通过将最长公共子字符串的长度除以最长字符串的长度来计算。
与子字符串不同,子序列不要求在原始序列中占据连续位置。因此,最长公共子序列总是大于最长公共子字符串。相似度得分的计算方式与后者相同。
以下示例:
>> s1, s2 = "RO PATTERN MATCHING", "RO PRACTICE"
>> td.lcsstr(s1, s2), td.lcsseq(s2, s1), td.lcsseq(s2, s1)
('RO P', 'RO PRATC', 'RO PRACI')
>> td.lcsstr.normalized_similarity(s1, s2), td.lcsseq.normalized_similarity(s1, s2)
(0.21, 0.42)
在上述示例中可以看到最长公共子字符串总是具有连续字符的子字符串,但在最长公共子序列中没有这个约束。
(A, B)的最长公共子序列与(B, A)不同。实际上可以在上面的例子中看到不同的结果(RO PRATC)和(RO PRACI)。
总结
在本文中,我们深入探讨了三个基本算法类别:基于编辑的算法、基于令牌的算法和基于序列的算法。需要记住的重要点是:
基于编辑的算法:
- Damerau-Levenshtein和Jaro winkler距离通过编辑操作量化字符级相似度。
- 适合强调单字符更改和更正的应用。
- 对于拼写检查、光学字符识别、字符精确度和文本自动纠正非常有价值。
基于令牌的算法:
- Jaccard 和Sørensen-Dice相似度关注令牌集,忽略序列。
- 对于文档聚类、抄袭检测和推荐系统有效。
- 强调存在而非顺序,有助于分类。
- 可用于内容分类和文档比较。
基于序列的算法:
- 最长公共子序列(LCS)和Ratcliff/Obershelp方法保留顺序。
- 对于DNA序列对齐、文本近重复检测和版本控制至关重要。
- 提供字符串内部结构关系的洞察。
没有单一的方法适用于所有情景,每一类算法都有其优势,适应特定的需求和背景。所以我们总结了这些算法,一个具备这些多样化技术知识的优秀数据科学家可以利用它们的综合力量来解决字符串相似度分析中的广泛挑战。
作者:Yassine EL KHAL
https://avoid.overfit.cn/post/43c11a3fee684fecb81eebf5647159aa